Shogun - A Large Scale Machine Learning Toolbox
 I am the main author of the SHOGUN machine learning toolbox which started with a Hidden Markov Model to be used for Splice Site Classification back in 1999 and was since then continuously extended by Gunnar Rätsch and me. Now its focus is on large scale kernel methods, especially Support Vector Machines. It comes with a generic interface for SVMs, features several SVM and kernel implementations, includes LinAdd optimizations and also Multiple Kernel Learning algorithms. SHOGUN also implements a number of linear methods. It allows the input feature-objects to be dense, sparse or strings and of type int/short/double/char.
I am the main author of the SHOGUN machine learning toolbox which started with a Hidden Markov Model to be used for Splice Site Classification back in 1999 and was since then continuously extended by Gunnar Rätsch and me. Now its focus is on large scale kernel methods, especially Support Vector Machines. It comes with a generic interface for SVMs, features several SVM and kernel implementations, includes LinAdd optimizations and also Multiple Kernel Learning algorithms. SHOGUN also implements a number of linear methods. It allows the input feature-objects to be dense, sparse or strings and of type int/short/double/char.
SHOGUN is implemented in C++ and interfaces to Matlab(tm), R, Octave and Python. A more exhaustive feature list can be found on its home page http://www.shogun-toolbox.org or its mloss.org project page.
LIBOCAS - Fast Linear SVM Training
 The library implements Optimized Cutting Plane Algorithm (OCAS) for efficient training of linear SVM classifiers from large-scale data.
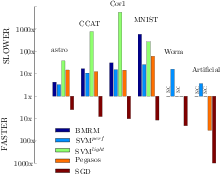
The computational effort of OCAS scales linearly with the sample size. In an extensive empirical evaluation OCAS significantly outperforms current state of the art SVM solvers, like SVM^light, SVM^perf and BMRM, achieving speedups of over 1,000 on some datasets over SVM^light and 20 over SVM^perf, while obtaining the same precise Support Vector solution.
Ocas is available from its
mloss.org project page.
The library implements Optimized Cutting Plane Algorithm (OCAS) for efficient training of linear SVM classifiers from large-scale data.
The computational effort of OCAS scales linearly with the sample size. In an extensive empirical evaluation OCAS significantly outperforms current state of the art SVM solvers, like SVM^light, SVM^perf and BMRM, achieving speedups of over 1,000 on some datasets over SVM^light and 20 over SVM^perf, while obtaining the same precise Support Vector solution.
Ocas is available from its
mloss.org project page.
MLOSS.ORG - Source code of MLOSS.ORG
This is the source code of the mloss.org website.
The website contains quite a few features and is also quite specific, so you may or may not find it useful for your means. The features include:
- a registration system for users of the site
- a database of user submitted software projects
- a rating system for the projects
- a commenting system for the projects
- access-statistics to the projects
- a blog (although articles have to be entered directly through django's admin interface)
- a forum
- email notifications for tracking projects and the forum
- a tool, which automatically extracts projects in the "machine learning" section from CRAN (a repository for packages for the R programming language)
 The source code is organized into several sub-directories, so called "applications". Each directory is organized more or less according to the django standard, at least containing a definition of the models in models.py, and of the url mappings in urls.py. If you want to find out how a specific url is processed, have a look at the urls.py, which tell you which method takes care of the request.
The source code is organized into several sub-directories, so called "applications". Each directory is organized more or less according to the django standard, at least containing a definition of the models in models.py, and of the url mappings in urls.py. If you want to find out how a specific url is processed, have a look at the urls.py, which tell you which method takes care of the request.
