Hello World
I have finally managed to setup a blog using handcrafted html and django. Having had the experience to write mloss.org, largescale.ml.tu-berlin.de and mldata.org my homepage here was done rather quickly (one weekend of hacking). If anyone is interested in website design I can really only recommend to use django. Work your way through the awesome tutorial or the book and get inspired by the sources of the many django based websites out there. Finally keep an eye on django code snippets that often contain small but useful functions and are solutions to problems you might have.
Shogun at Google Summer of Code 2011
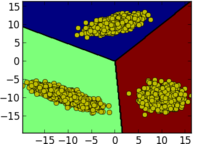
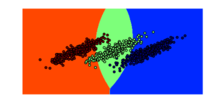
Google Summer of Code 2011 gave a big boost to the development of the shogun machine learning toolbox. In case you have never heard of shogun or machine learning: Machine Learning involves algorithms that do ``intelligent'' and even automatic data processing and is nowadays used everywhere to e.g. do face detection in your camera, compress the speech in you mobile phone, powers the recommendations in your favourite online shop, predicts solulabily of molecules in water, the location of genes in humans, to name just a few examples. Interested? Then you should give it a try. Some very simple examples stemming from a sub-branch of machine learning called supervised learning illustrate how objects represented by two-dimensional vectors can be classified in good or bad by learning a so called support vector machine. I would suggest to install the python_modular interface of shogun and to run the example interactive_svm_demo.py also included in the source tarball. Two images illustrating the training of a support vector machine follow (click to enlarge):
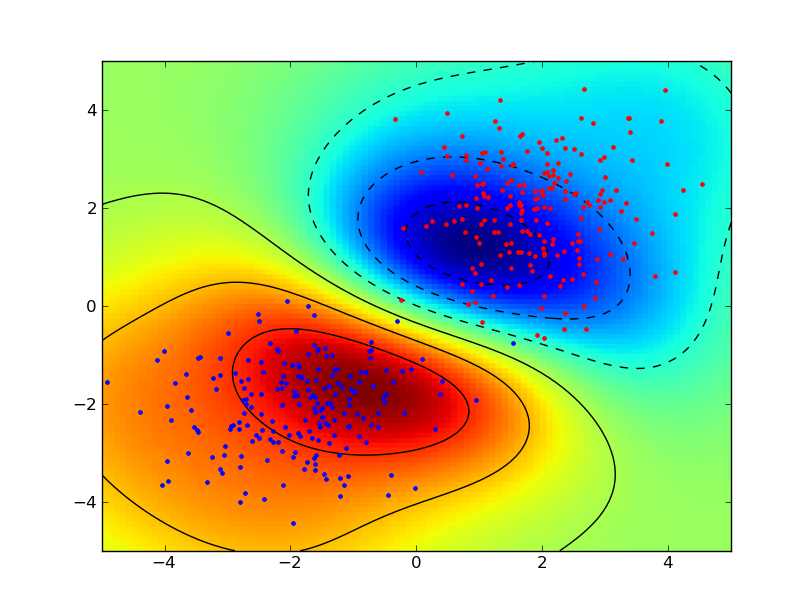
Now back to Google Summer of Code: Google sponsored 5 talented students who were working hard on various subjects. As a result we now have a new core developer and various new features implemented in shogun: Interfaces to new languages like java, c#, ruby, lua written by Baozeng; A model selection framework written by Heiko Strathman, many dimension reduction techniques written by Sergey Lisitsyn, Gaussian Mixture Model estimation written by Alesis Novik and a full-fledged online learning framework developed by Shashwat Lal Das. All of this work has already been integrated in the newly released shogun 1.0.0. In case you want to know more about the students projects continue reading below, but before going into more detail I would like to summarize my experience with GSoC 2011.
My Experience with Google Summer of Code
We were a first time organization, i.e. taking part for the first time in GSoC. Having received many many student applications we were very happy to hear that we at least got 5 very talented students accepted but still had to reject about 60 students (only 7% acceptance rate!). Doing this was an extremely tough decision for us. Each of us ended up in scoring students even then we had many ties. So in the end we raised the bar by requiring contributions even before the actual GSoC started. This way we already got many improvements like more complete i/o functions, nicely polished ROC and other evaluation routines, new machine learning algorithms like gaussian naive bayes and averaged perceptron and many bugfixes.
The quality of the contributions and independence of the student aided us coming up with the selection of the final five.
I personally played the role of the administrator and (co-)mentor and scheduled regular (usually) monthly irc meetings with mentors and students. For other org admins or mentors wanting into GSoC here come my lessons learned:
- Set up the infrastructure for your project before GSoC: We transitioned from svn to git (on github) just before GSoC started. While it was a bit tough to work with git in the beginning it quickly payed off (patch reviewing and discussions on github were really much more easy). We did not have proper regression tests running daily during most of GSoC leaving a number of issues undetected for quite some time. Now that we have buildbots running I keep wondering how we could survive for so long without them :-)
- Even though all of our students worked very independently, you want to mentor them very closely in the beginning such that they write code that you like to see in your project, following coding style, utilizing already existing helper routines. We did this and it simplified our lives later - we could mostly accept patches as is.
- Expect contributions from external parties: We had contributions to shogun's ruby and csharp interfaces/examples. Ensure that you have some spare manpower to review such additional patches.
- Expect critical code review by your students and be open to restructure the code. As a long term contributer you probably no longer realize whether your class-design / code structure is hard to digest. Freshmans like GSoC students immediately will when they stumble upon inconsitencies. When they discover such issues, discuss with them how to resolve them and don't be afraid of doing even bigger changes in the early GSoC phase (not too big to hinder work of all of your students though). We had quite some structural improvent in shogun due to several suggestions by our students. Overall the project improved drastically - not just w.r.t. additions.
- As a mentor, work with your student on the project. Yes, get your hands dirty too. This way you are much more of an help to the student when things get stuck and it will be much easier for you to answer difficult questions.
- As a mentor, try to answer the questions your students have within a few hours. This keeps the students motivated and you excited that they are doing a great job.
Now please read on to learn about the newly implemented features:
Dimension Reduction Techniques
Sergey Lisitsyn (Mentor: Christian Widmer)Dimensionality reduction is the process of finding a low-dimensional representation of a high-dimensional one while maintaining the core essence of the data. For one of the most important practical issues of applied machine learning, it is widely used for preprocessing real data. With a strong focus on memory requirements and speed, Sergey implemented the following dimension reduction techniques:
- Locally Linear Embedding
- Kernel Locally Linear Embedding
- Local Tangent Space Alignment
- Multidimensional scaling (with capability of landmark approximation)
- Isomap
- Hessian Locally Linear Embedding
- Laplacian Eigenmaps
See below for the some nice illustrations of dimension reduction/embedding techniques (click to enlarge).
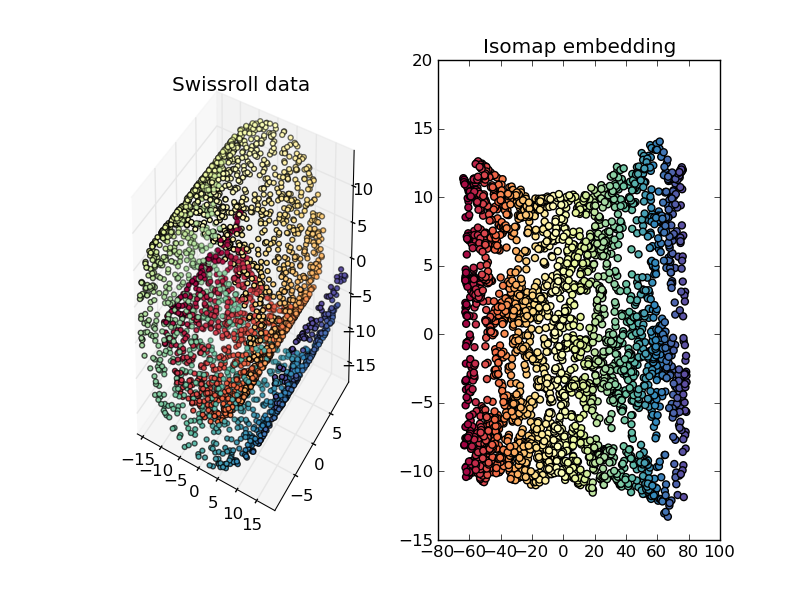
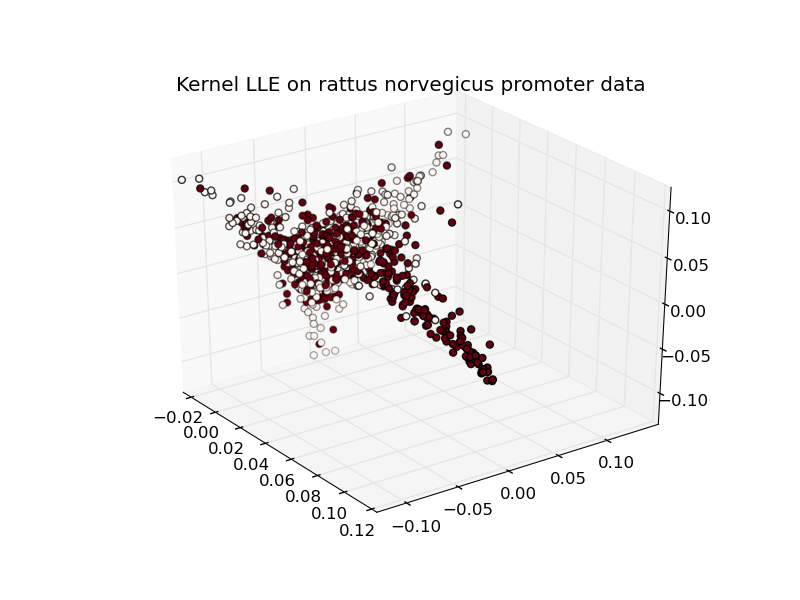
.png)
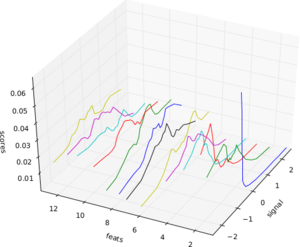
Cross-Validation Framework
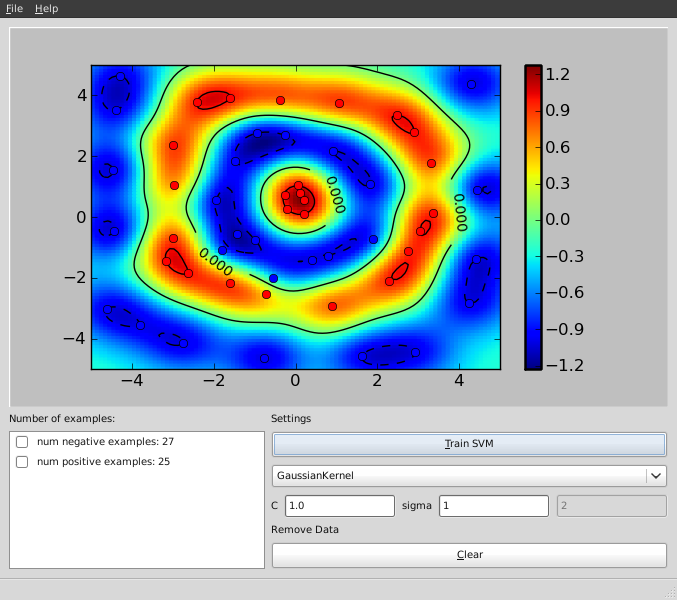
Heiko Strathmann (Mentor: Soeren Sonnenburg)Nearly every learning machine has parameters which have to be determined manually. Before Heiko started his project one had to manually implement cross-validation using (nested) for-loops. In his highly involved project Heiko extend shogun's core to register parameters and ultimately made cross-validation possible. He implemented different model selection schemes (train,validation,test split, n-fold cross-validation, stratified cross-validation, etc and did create some examples for illustration. Note that various performance measures are available to measure how ``good'' a model is. The figure below shows the area under the receiver operator characteristic curve as an example.
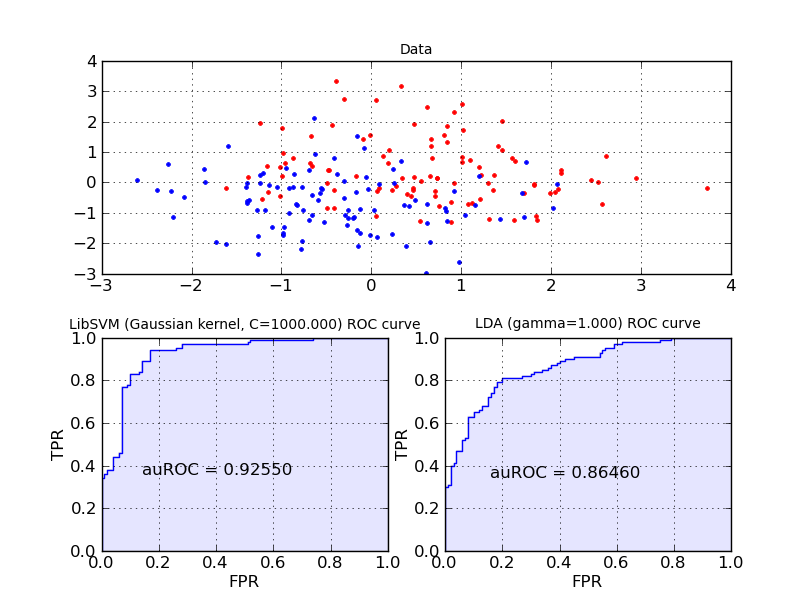
Interfaces to the Java, C#, Lua and Ruby Programming Languages
Baozeng (Mentor: Mikio Braun and Soeren Sonnenburg)Boazeng implemented swig-typemaps that enable transfer of objects native to the language one wants to interface to. In his project, he added support for Java, Ruby, C# and Lua. His knowlegde about swig helped us to drastically simplify shogun's typemaps for existing languages like octave and python resolving other corner-case type issues. The addition of these typemaps brings a high-performance and versatile machine learning toolbox to these languages. It should be noted that shogun objects trained in e.g. python can be serialized to disk and then loaded from any other language like say lua or java. We hope this helps users working in multiple-language environments. Note that the syntax is very similar across all languages used, compare for yourself - various examples for all languages ( python, octave, java, lua, ruby, and csharp) are available.
Largescale Learning Framework and Integration of Vowpal Wabbit
Shashwat Lal Das (Mentor: John Langford and Soeren Sonnenburg)Shashwat introduced support for 'streaming' features into shogun. That is instead of shogun's traditional way of requiring all data to be in memory, features can now be streamed from e.g. disk, enabling the use of massively big data sets. He implemented support for dense and sparse vector based input streams as well as strings and converted existing online learning methods to use this framework. He was particularly careful and even made it possible to emulate streaming from in-memory features. He finally integrated (parts of) vowpal wabbit, which is a very fast large scale online learning algorithm based on SGD.
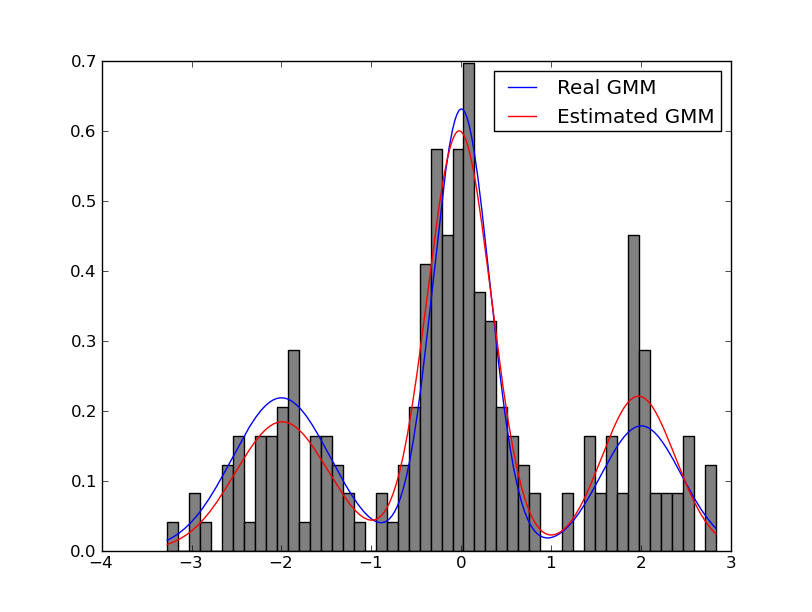
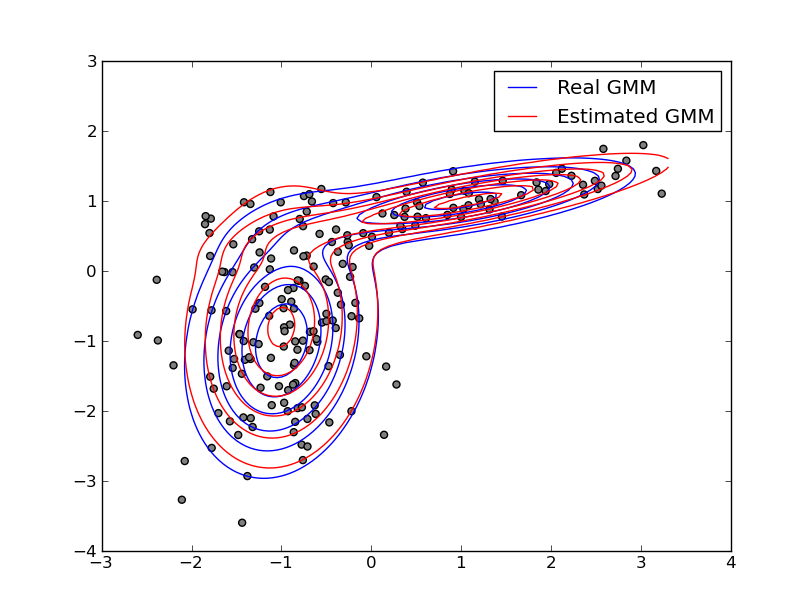
Expectation Maximization Algorithms for Gaussian Mixture Models
Alesis Novik (Mentor: Vojtech Franc)The Expectation-Maximization algorithm is well known in the machine learning community. The goal of this project was the robust implementation of the Expectation-Maximization algorithm for Gaussian Mixture Models. Several computational tricks have been applied to address numerical and stability issues, like
- Representing covariance matrices as their SVD
- Doing operations in log domain to avoid overflow/underflow
- Setting minimum variances to avoid singular Gaussians.
- Merging/splitting of Gaussians.
Final Remarks
All in all, this year’s GSoC has given the SHOGUN project a great push forward and we hope that this will translate into an increased user base and numerous external contributions. Also, we hope that by providing bindings for many languages, we can provide a neutral ground for Machine Learning implementations and that way bring together communities centered around different programming languages. All that’s left to say is that given the great experiences from this year, we’d be more than happy to participate in GSoC2012.
Google Summer of Code Mentors Summit 2011
Google mentors summit 2011 is over. It is hard to believe but we had way more discussions about open science, or open data, open source, and open access than on all machine learning open source software workshops combined. Well, and the number of participants oft the science sessions was unexpectedly high too. One of the interesting suggestions was the science code manifesto suggesting among other things that all code written specifically for a paper must be available to the reviewers and readers of the paper. I think that this can nicely be extended to data too and really should receive wide support!
Besides such high goals the summit was a good occasion to get in touch with core developers of git, opencv, llvm/clang, orange, octave, python... and discuss about concrete collaborations, issues and bugs that the shogun toolbox is triggering. So yes I already fixed some and more to come. Thanks google for sponsoring this - it's been a very nice event.

Shogun got accepted at Google Summer of Code 2012
SHOGUN has been accepted for Google Summer of Code 2012.
SHOGUN is a machine learning toolbox, which is designed for unified large-scale learning for a broad range of feature types and learning settings. It offers a considerable number of machine learning models such as support vector machines for classification and regression, hidden Markov models, multiple kernel learning, linear discriminant analysis, linear programming machines, and perceptrons. Most of the specific algorithms are able to deal with several different data classes, including dense and sparse vectors and sequences using floating point or discrete data types. We have used this toolbox in several applications from computational biology, some of them coming with no less than 10 million training examples and others with 7 billion test examples. With more than a thousand installations worldwide, SHOGUN is already widely adopted in the machine learning community and beyond.
SHOGUN is implemented in C++ and interfaces to all important languages like MATLAB, R, Octave, Python, Lua, Java, C#, Ruby and has a stand-alone command line interface. The source code is freely available under the GNU General Public License, Version 3 at http://www.shogun-toolbox.org.
During Summer of Code 2012 we are looking to extend the library in three different ways:
- Improving accessibility to shogun by developing improving i/o support (more file formats) and mloss.org/mldata.org integration.
- Framework improvements (frameworks for regression, multiclass, structured output problems, quadratic progamming solvers).
- Integration of existing and new machine algorithms.
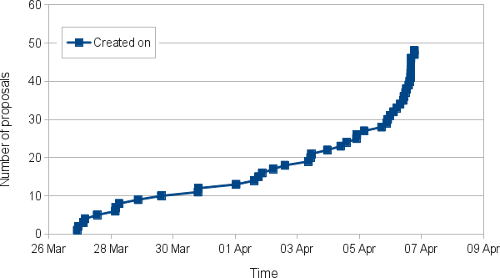
Shogun Student Applications Statistics for Google Summer of Code 2012
A few weeks have passed since SHOGUN has been accepted for Google Summer of Code 2012. Student application deadline was Easter Friday (April 6) and shogun received 48 proposals from 38 students. Some more detailed stats can be found in the figure below.
- One has to get shogun to compile (possibly only easy under debian; for cygwin/MacOSX you have to invest quite some time to even get all of its dependencies).
- One has to become familiar with git, github and learn how to issue a pull request.
- And finally understand enough of machine learning, shogun's source code to be able to fix a bug or implement some baseline machine learning method
GSoC2012 Accepted Students
Shogun has received an outstanding 9 slots in this years google summer of code. Thanks to google and the hard work of our mentors ranking and discussing with the applicants - we were able to accept 8 talented students (We had to return one slot back to the pool due to not having enough mentors for all tasks. We indicated that octave gets the slot so lets hope they got it and will spend it well :).
![]()
Each of the students will work on rather challenging machine learning topics.
The accepted topics and the students attacking them with the help of there mentors are
- Kernel Two-sample/Dependence test
- Student: Heiko Strathmann
- Mentor: Arthur Gretton, Soeren Sonnenburg
- Abstract
- Implement multitask and domain adaptation algorithms
- Student: Sergej Lisityn
- Mentor: Christian Widmer
- Abstract
- Implementation of / Integration via existing GPL code of latent SVMs.
- Student: Viktor Gal
- Mentor: Alexander Binder
- Abstract
- Bundle method solver for structured output learning
- Student: Michal Uricar
- Mentor: Vojtech Franc
- Abstract
- Built generic structured output learning framework
- Student: Fernando Jose Iglesias Garcia
- Mentor: Nico Goernitz
- Abstract
- Improving accessibility to shogun
- Student: Evgeniy Andreev
- Mentor: Soeren Sonnenburg
- Abstract
- Implement Gaussian Processes and regression techniques
- Student: Jacob Walker
- Mentor: Oliver Stegle
- Abstract
- Built generic multiclass learning framework
- Student: Chiyuan Zhang
- Mentor: Cheng Soon Ong
- Abstract
We are excited to have them all in the team! Happy hacking!
Shogun at Google Summer of Code 2012
The summer came finally to an end and (yes in Berlin we still had 20 C end of October), unfortunately, so did GSoC with it. This has been the second time for SHOGUN to be in GSoC. For those unfamiliar with SHOGUN - it is a very versatile machine learning toolbox that enables unified large-scale learning for a broad range of feature types and learning settings, like classification, regression, or explorative data analysis. I again played the role of an org admin and co-mentor this year and would like to take the opportunity to summarize enhancements to the toolbox and my GSoC experience: In contrast to last year, we required code-contributions in the application phase of GSoC already, i.e., a (small) patch was mandatory for your application to be considered. This reduced the number of applications we received: 48 proposals from 38 students instead of 70 proposals from about 60 students last year but also increased the overall quality of the applications.
In the end we were very happy to get 8 very talented students and have the opportunity of boosting the project thanks to their hard and awesome work. Thanks to google for sponsoring three more students compared to last GSoC. Still we gave one slot back to the pool for good to the octave project (They used it very wisely and octave will have a just-in-time compiler now, which will benefit us all!).
SHOGUN 2.0.0 is the new release of the toolbox including of course all the new features that the students have implemented in their projects. On the one hand, modules that were already in SHOGUN have been extended or improved. For example, Jacob Walker has implemented Gaussian Processes (GPs) improving the usability of SHOGUN for regression problems. A framework for multiclass learning by Chiyuan Zhang including state-of-the-art methods in this area such as Error-Correcting Output Coding (ECOC) and ShareBoost, among others. In addition, Evgeniy Andreev has made very important improvements w.r.t. the accessibility of SHOGUN. Thanks to his work with SWIG director classes, now it is possible to use python for prototyping and make use of that code with the same flexibility as if it had been written in the C++ core of the project. On the other hand, completely new frameworks and other functionalities have been added to the project as well. This is the case of multitask learning and domain adaptation algorithms written by Sergey Lisitsyn and the kernel two-sample or dependence test by Heiko Strathmann. Viktor Gal has introduced latent SVMs to SHOGUN and, finally, two students have worked in the new structured output learning framework. Fernando Iglesias made the design of this framework introducing the structured output machines into SHOGUN while Michal Uricar has implemented several bundle methods to solve the optimization problem of the structured output SVM.
It has been very fun and interesting how the work done in different projects has been put together very early, even during the GSoC period. Only to show an example of this dealing with the generic structured output framework and the improvements in the accessibility. It is possible to make use of the SWIG directors to implement the application specific mechanisms of a structured learning problem instance in python and then use the rest of the framework (written in C++) to solve this new problem.
Students! You all did a great job and I am more than amazed what you all have achieved. Thank you very much and I hope some of you will stick around.
Besides all these improvements it has been particularly challenging for me as org admin to scale the project. While I could still be deeply involved in each and every part of the project last GSoC, this was no longer possible this year. Learning to trust that your mentors are doing the job is something that didn't come easy to me. Having had about monthly all-hands meetings did help and so did monitoring the happiness of the students. I am glad that it all worked out nicely this year too. Again, I would like to mention that SHOGUN improved a lot code-base/code-quality wise. Students gave very constructive feedback about our (lack) of proper Vector/Matrix/String/Sparse Matrix types. We now have all these implemented doing automagic memory garbage collection behind scenes. We have started to transition to use Eigen3 as our matrix library of choice, which made quite a number of algorithms much easier to implement. We generalized the Label framework (CLabels) to be tractable for not just classification and regression but multitask and structured output learning.
Finally, we have had quite a number of infrastructure improvements. Thanks to GSoC money we have a dedicated server for running the buildbot/buildslaves and website. The ML Group at TU Berlin does sponsor virtual machines for building SHOGUN on Debian and Cygwin. Viktor Gal stepped up providing buildslaves for Ubuntu and FreeBSD. Gunnar Raetschs group is supporting redhat based build tests. We have Travis CI running testing pull requests for breakage even before merges. Code quality is now monitored utilizing LLVMs scan-build. Bernard Hernandez appeared and wrote a fancy new website for SHOGUN.
A more detailed description of the achievements of each of the students follows:- Kernel Two-sample/Dependence test
- Student: Heiko Strathmann
- Mentor: Arthur Gretton, Soeren Sonnenburg
Heiko Strathmann, mentored by Arthur Gretton, worked on a framework for kernel-based statistical hypothesis testing. Statistical tests to determine whether two random variables are are equal/different or are statistically independent are an important tool in data-analysis. However, when data are high-dimensional or in non-numerical form (documents, graphs), classical methods fail. Heiko implemented recently developed kernel-based generalisations of classical tests which overcome these issues by representing distributions in high dimensional so-called reproducing kernel Hilbert spaces. By doing so, theoretically any pair samples can be distinguished.
Implemented methods include two-sample testing with the Maximum Mean Discrepancy (MMD) and independence testing using the Hilbert Schmidt Independence Criterion (HSIC). Both methods come in different flavours regarding computational costs and test constructions. For two-sample testing with the MMD, a linear time streaming version is included that can handle arbitrary amounts of data. All methods are integrated into a newly written flexible framework for statistical testing which will be extended in the future. A book-style tutorial with descriptions of algorithms and instructions how to use them is also included.
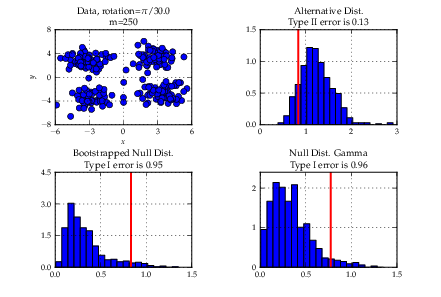
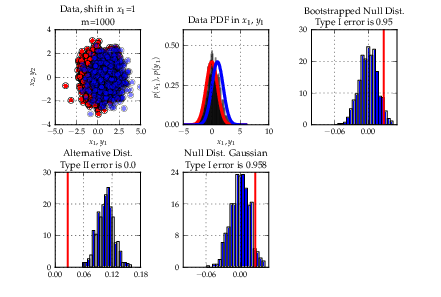
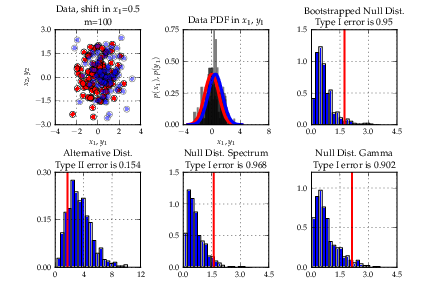
- Implement multitask and domain adaptation algorithms
- Student: Sergey Lisityn
- Mentor: Christian Widmer
Like Heiko, Sergey Lisitsyn did participate in the GSoC programme for the second time. This year he focused on implementing multitask learning algorithms. Multitask learning is a modern approach to machine learning that learns a problem together with other related problems at the same time using a shared representation. This approach often leads to a better model for the main task, because it allows the learner to use the commonality among the tasks. During the summer Sergey has ported a few algorithms from the SLEP and MALSAR libraries with further extensions and improvements. Namely, L12 group tree and L1q group multitask logistic regression and least squares regression, trace-norm multitask logistic regression, clustered multitask logistic regression, basic group and group tree lasso logistic regression. All the implemented algorithms use COFFIN framework for flexible and efficient learning and some of the algorithms were implemented efficiently utilizing the Eigen3 library.
- Implementation of / Integration via existing GPL code of latent SVMs.
- Student: Viktor Gal
- Mentor: Alexander Binder
A generic latent SVM and additionally a latent structured output SVM has been implemented. This machine learning algorithm is widely used in computer vision, namely in object detection. Other useful application fields are: motif finding in DNA sequences, noun phrase coreference, i.e. provide a clustering of the nouns such that each cluster refers to a single object.
It is based on defining a general latent feature Psi(x,y,h) depending on input variable x, output variable y and latent variable h. Deriving a class from the base class allows the user to implement additional structural knowledge for efficient maximization of the latent variable or alternative ways of computation or on-the-fly loading of latent features Psi as a function of the input, output and latent variables.
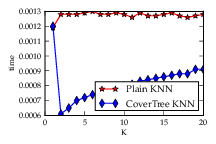
- Bundle method solver for structured output learning
- Student: Michal Uricar
- Mentor: Vojtech Franc
We have implemented two generic solvers for supervised learning of structured output (SO) classifiers. First, we implemented the current state-of-the-art Bundle Method for Regularized Risk Minimization (BMRM) [Teo et al. 2010]. Second, we implemented a novel variant of the classical Bundle Method (BM) [Lamarechal 1978] which achieves the same precise solution as the BMRM but in time up to an order of magnitude shorter [Uricar et al. 2012].
Among the main practical benefits of the implemented solvers belong their modularity and proven convergence guarantees. For training a particular SO classifier it suffices to provide the solver with a routine evaluating the application specific risk function. This feature is invaluable for designers who can concentrate on tuning the classification model instead of spending time on developing new optimization solvers. The convergence guarantees remove the uncertainty inherent in use of on-line approximate solvers.
The implemented solvers have been integrated to the structured output framework of the SHOGUN toolbox and they have been tested on real-life data.
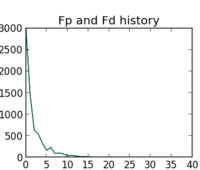
- Built generic structured output learning framework
- Student: Fernando Jose Iglesias Garcia
- Mentor: Nico Goernitz
During GSoC 2012 Fernando implemented a generic framework for structured output (SO) problems. Structured output learning deals with problems where the prediction made is represented by an object with complex structure, e.g. a graph, a tree or a sequence. SHOGUN's SO framework is flexible and easy to extend [1]. Fernando implemented a naïve cutting plane algorithm for the SVM approach to SO [2]. In addition, he coded a case of use of the framework for labelled sequence learning, the so-called Hidden Markov SVM. The HM-SVM can be applied to solve problems in different fields such as gene prediction in bioinformatics or speech to text in pattern recognition.
[1] Class diagram of the SO framework.
[2] Support Vector Machine Learning for Interdependent and Structured Output Spaces. - Improving accessibility to shogun
- Student: Evgeniy Andreev
- Mentor: Soeren Sonnenburg
During the latest google summer of code Evgeniy has improved the Python modular interface. He has added new SWIG-based feature - director classes, enabling users to extend SHOGUN classes with python code and made SHOGUN python 3 ready. Evgeniy has also added python's protocols for most usable arrays (like vectors, matrices, features) which makes possible to work with Shogun data structures just like with numpy arrays with no copy at all. For example one can now modify SHOGUN's RealFeatures in place or use.
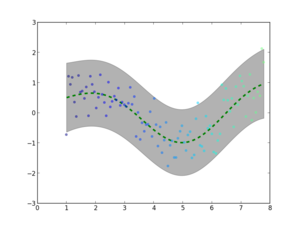
- Implement Gaussian Processes and regression techniques
- Student: Jacob Walker
- Mentor: Oliver Stegle
Jacob implemented Gaussian Process Regression in the Shogun Machine Learning Toolbox. He wrote a complete implementation of basic GPR as well as approximation methods such as the FITC (First Independent Training Conditional) method and the Laplacian approximation method. Users can utilize this feature to analyze large scale data in a variety of fields. Scientists can also build on this implementation to conduct research extending the capability and applicability of Gaussian Process Regression.
- Build generic multiclass learning framework
- Student: Chiyuan Zhang
- Mentor: Cheng Soon Ong
Chiyuan defined a new multiclass learning framework within SHOGUN. He re-organized previous multiclass learning components and refactored the CMachine hierarchy in SHOGUN. Then he generalized the existing one-vs-one and one-vs-rest multiclass learning scheme to general ECOC encoding and decoding strategies. Beside this, several specific multiclass learning algorithms are added, including ShareBoost with feature selection ability, Conditional Probability Tree with online learning ability, and Relaxed Tree.
Shogun at PyData NYC 2012
Christian Widmer gave a talk about the shogun machine learning toolbox version 2.0 at PyData NYC 2012. His talk is finally available as a video online.
Shogun Toolbox Days 2013 - Give Your Data a Treat
Shogun Toolbox Days 2013 - Give Your Data a Treat
Dear all, save the date - July 12, 2013!
we just received confirmation from the c-base crew [1], [2] - the first shogun machine learning toolbox workshop will take place at c-base this Summer July 12 in Berlin! Anyone interested in participating / this event / or interested in helping to organize it - please talk to us on IRC or post on the mailinglist...
Shogun Toolbox Version 2.1.0 Released!
We have just released shogun 2.1.0. This release contains over 800 commits since 2.0.0 with a load of bugfixes, new features and improvements (see the changelog for details) that make Shogun more efficient, robust and versatile. In particular, Christian Montanari developed a first alpha version of a perl modular interface, Heiko Strathmann did add Linear Time MMD on Streaming Data, Viktor Gal wrote a new structured output solver and Sergey Lisitsyn added support for tapkee - a dimension reduction framework. Read more at http://www.shogun-toolbox.org
