COFFIN: Computational Framework for Linear SVMs
Supplementary Material to our ICML paper COFFIN
In a variety of applications, kernel machines such as Support Vector Machines (SVMs) have been used with great success often delivering state-of-the-art results. Using the kernel trick, they work on several domains and even enable heterogeneous data fusion by concatenating feature spaces or multiple kernel learning. Unfortunately, they are not suited for truly large-scale applications since they suffer from the curse of supporting vectors, e.g., the speed of applying SVMs decays linearly with the number of support vectors. In this paper we develop COFFIN --- a new training strategy for linear SVMs that effectively allows the use of on demand computed kernel feature spaces and virtual examples in the primal. With linear training and prediction effort this framework leverages SVM applications to truly large-scale problems: As an example, we train SVMs for human splice site recognition involving 50 million examples and sophisticated string kernels. Additionally, we learn an SVM based gender detector on 5 million examples on low-tech hardware and achieve beyond the state-of-the-art accuracies on both tasks.
Results - Speed and Accuracy
Table 1 in the paper is visualized in the following two figures, demonstrating the huge speedup that can be achieved using COFFIN.

This figure illustrates how the training time evolves with growing data set size. Since this is a log-log plot, slopes of the curves correspond to exponents in the efforts (i.e., m^slope). Notably, COFFIN is much faster across all hash sizes than linadd. Complexity of COFFIN with the linear SVM solvers remains about linear (slope 1). However, note that linadd is still rather efficient (slope of about 1.5) and still way below the quadratic/cubic complexity of training SVMs in the dual.
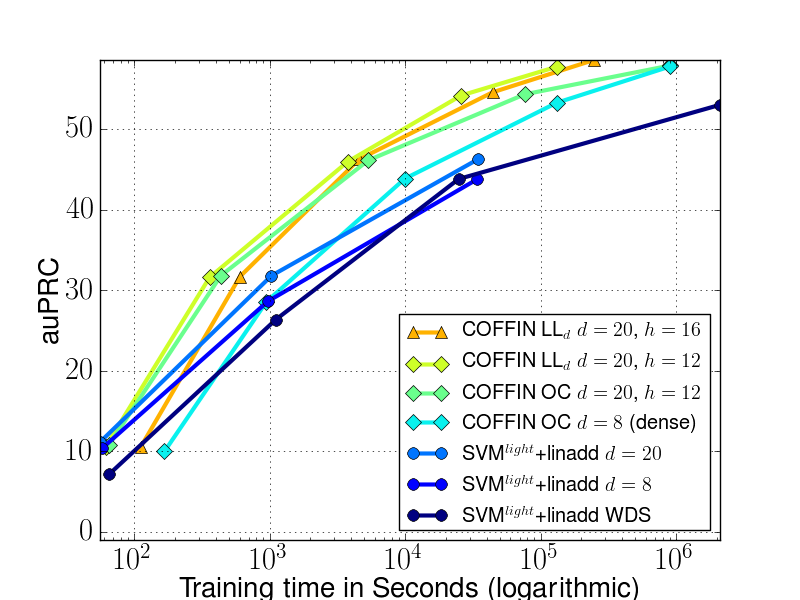
This figure illustrates how the area under the precision recall curve (auPRC) evolves with training time. Note that the different points here correspond to training COFFIN to full precision on different data set sizes (up to 50 million examples).
Results - Impact of Hash Size
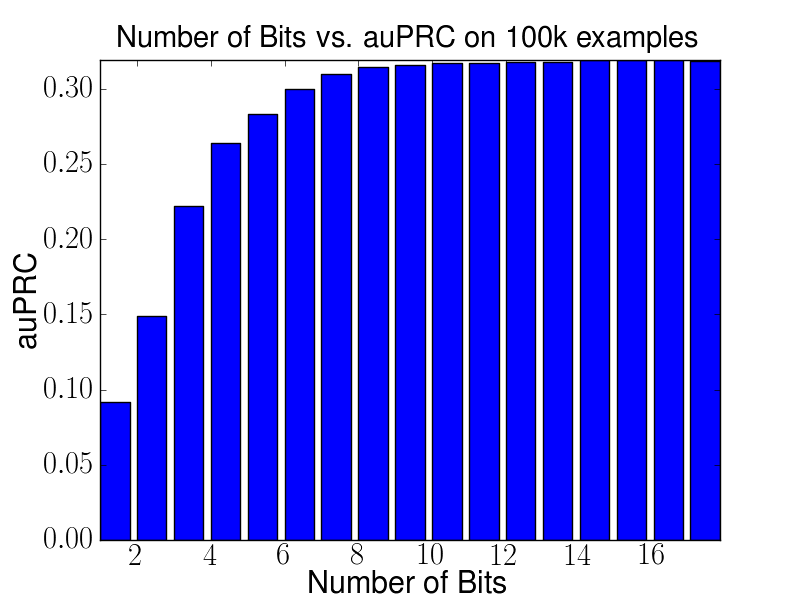
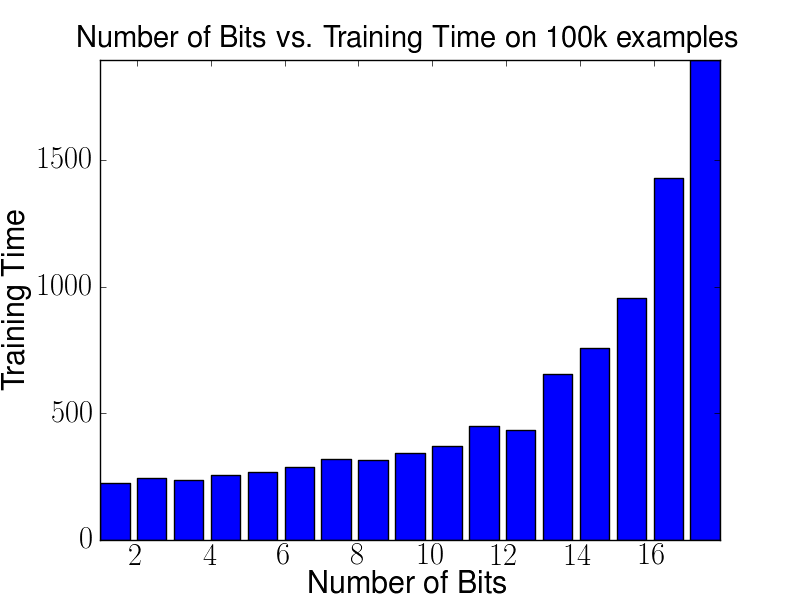
The following two figures display Performance in terms of area under the precision recall curve (auPRC) and training times on the human acceptor splice site experiment using 100,000 examples and varying bit sizes for the hash of the central WD kernel. For this experiment OCAS was used. It can be seen that already starting with about 8-10 bits the auPRC reaches a plateau. In addition, training times start to drastically increase as soon as hashes of more than 12 bit are used. This drop in performance indicates that the whole hash-table does no longer fit in the CPU data cache for larger hash tables. For 12bits w is 11,725,480 dimensional.
Source code
The dynamic feature space generation part of COFFIN is readily integrated in the shogun machine learning toolbox (since version 0.9.1). The concept of virtual on-demand computed examples can be easily realized within shogun by creating an additional feature object that is based on e.g. string or real values features. Such feature object would then return virtual features computed based on the original ones when get_feature_vector() (or the like) is called.
The gender classification experiment was carried out using SVM Ocas version 0.93 with additional matlab scripts to process the images.
Data sets and Scripts
Bioinformatics Example: Splice site recognition
The splice site datasets can be loaded from here. WARNING these dataset are 27GB in size when uncompressed and already the compressed archive is 1.6GB in size!!!. Note that you will need XZ Utils to decompress the archive (bzip2 -9 compression results in 3.2GB hence it is very much worth the effort to use xz compression in this case). For convenience, the md5sums of the uncompressed archive and the compressed archive are 0f739ecb3f665fedb794e8f9532f3b26 and 4bd0be48ae163ea9f4893e5a5c423c79 respectively. The corresponding scripts to re-do the experiments and plot the figures are available from here
Image Example: Gender Classification
The gender classification experiment was carried out using SVM Ocas version 0.93 with additional matlab scripts to process the images. The dataset used in this paper cannot be made publicly available (due to privacy concerns). However a small toy dataset is provided to illustrate the concept on the ocas homepage.
